
この記事では、Auth0 の Hernán Meydac Jean とその Site Reliability Engineering (SRE) チームが実施した、可用性と信頼性の高い成熟したサービス アーキテクチャの段階的な構築方法について説明します。
Auth0 は、クライアント向けにさまざまな機能を展開しています。その 1 つである機能フラグを使用すると、機能をコードベースで有効化できるため、不具合が起きるリスクやコードを変更する手間を減らすことができます。機能フラグは「機能トグル」とも言いますが、Pete Hodgson 氏が定義しているとおり、開発者がコードを変更せずにシステムの動作を変更することができる柔軟性の高い手法です。機能フラグを使用すれば、稼働中のシステムでも開発チームが機能のオンとオフを切り替えられます。
機能フラグ ルーター サービスを作成したきっかけ
機能フラグ ルーター サービスを作成することにしたのは、機能フラグを簡単に管理できるようにしたいというのがきっかけでした。Martin Fowler 氏が定義したとおり、機能フラグ ルーターを使用すれば、どの機能コード パスを有効にするかを動的に制御することができます。このルーターではすべての機能フラグ ロジックを一元的に管理できるため、複数のサービスや製品からいつでも同じ情報を取得して、あらゆる機能でフラグのオンとオフを切り替えることがで
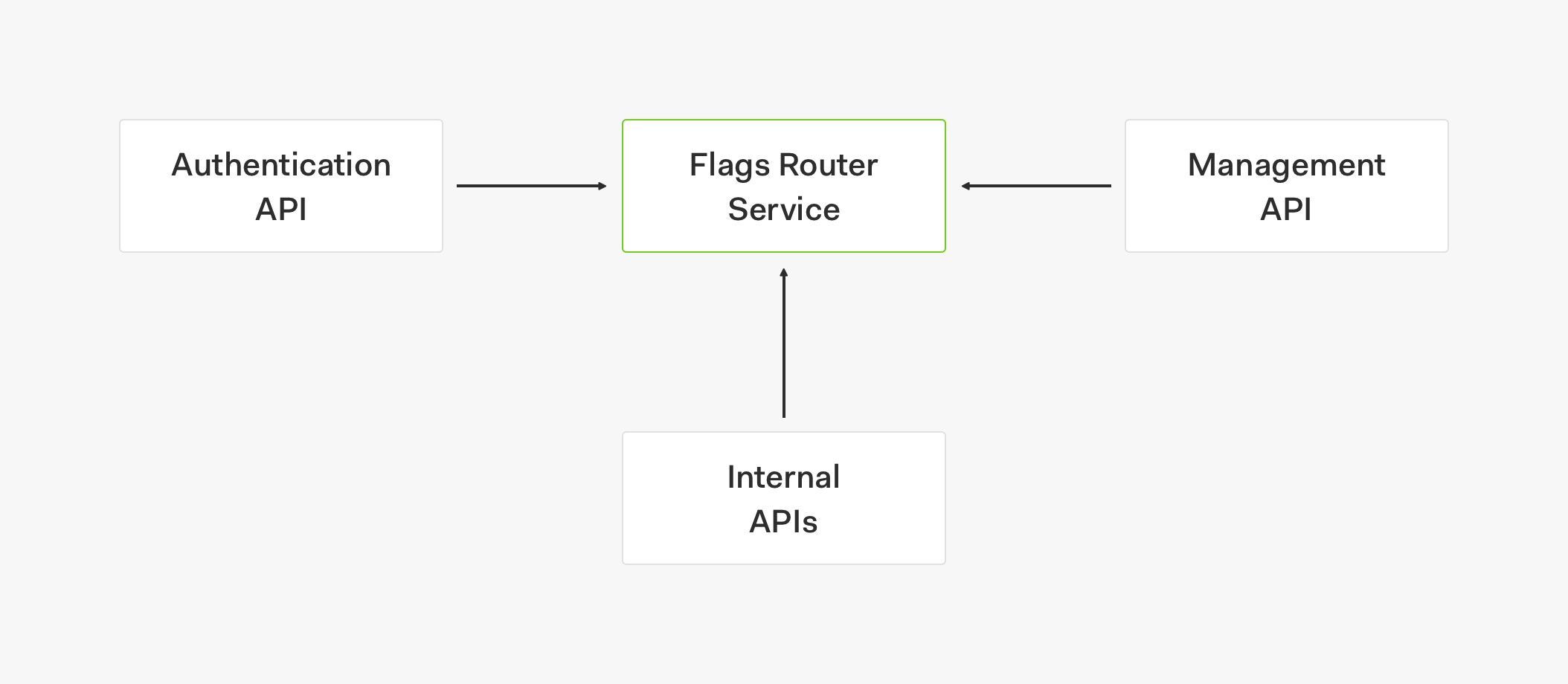
私たちは、この機能フラグ ルーター サービスを組織内外のさまざまな製品やサービスで使用できる汎用的なサービスにしたいと考えています。このサービスで今後かなりの数のクライアントをサポートすることになることや、そのクライアントからリクエストが大量に生成されるようになることを考えると、アーキテクチャは簡単に拡張できるものにし、可用性も高められる設計にする必要があると考えました。
機能の同等性を維持する SDK の設計
SRE チームはこの考えをベースに機能フラグ SDK を考案しました。抽象的なクライアントとして動作するよう設計し、あらゆる種類のプロバイダーやデータベースを使用できるようにしました。目指したのは、どのサービスでも同じ言語と同じ構文を使用できる SDK にすることです。そうすれば SDK で容易に同じコードを提供できるため、機能フラグの値を取得するためにデータベースに直接アクセスしたり、サーバーに直接リクエストしたりする必要がなくなります。また、SDK のロジックを変更する必要がある場合には、SDK のバージョンを上げて更新を適用するだけです。
“@auth0 SRE チームがどのように機能フラグの管理と機能の同等性を後押しする標準ライブラリを作成したのかをご紹介します”
Tweet This
この SDK クライアントの最終設計は、フォールバック、自己回復機能、高い可用性と拡張性を段階的に実装するサービス アーキテクチャとなりました。まず、クライアントからデータベースへの直接アクセスを可能にする基本的なトポロジを構築し、最終的に、機能フラグ ルーター サービスの自己回復戦略を組み込んだ高機能のトポロジを実装します。
では、Auth0 社内で Hernán が説明した内容をベースに、このシステム トポロジの構築プロセスの各段階について見ていきましょう。これらのトポロジを抽象化することで、あらゆるプロバイダーや多様なデータベースを使用できるようになります。
信頼性や拡張性の課題に挑戦しませんか? Auth0 では SRE チームのエンジニアを募集しています!
データベースへの直接接続
まず、クライアントから MongoDB などのデータベースに直接接続できるようにします。これはこのサービスに必要な最も基本的な構成で、クライアントから任意のデータベースに接続し、データ (このケースでは機能フラグ) を取得します。このクライアントは、読み取り専用のアクセス許可しか持てないように制限されますが、必要な場合は書き込み許可を追加することもできます。

Auth0 の機能フラグ サービスのクライアントは現在、読み取り専用となっています。
ではこのアーキテクチャのメリットとデメリットを見てみましょう。
メリット
- セットアップが簡単
- 追加のインフラストラクチャが不要
- Auth0 アプライアンス用に構成できる
- Auth0 アプライアンスとは、Auth0 のクラウド、お客様のクラウド、お客様のデータセンターの専用領域に展開されている Auth0 環境を指します。
- たとえば、Auth0 でセルフホストしているインスタンスならサービスを管理する Auth0 サーバーに接続する必要はなく、データベースに直接接続できます。
デメリット
- フェールオーバーがない
- データベースが停止すると、サービスも停止します。
- クライアント アプリケーション側で制限しない限り、データベースに負荷がかかる
- セキュリティが複雑になる
- サービスにデータベースへのアクセスを許可する必要があります。
- データベースへのアクセス レベルをサービスごとに制御するには、アクセス許可を発行してセキュリティ グループを作成するなどの処理が必要になります。
この構成は基本的なものですが、私たちはさらに良い方法として、このサービス アーキテクチャに「ストア」の概念を組み込むことにしました。
データ ストアの利用
先ほどのサービス アーキテクチャを強化するために、ストアの概念を導入しました。ストアは、サービス プロバイダーのことです。プライマリ プロバイダーやセカンダリ プロバイダーであり、そこからさまざまなサービスに接続できます。サービスは API だったり、データベースへの直接接続だったりします。基本的には、ストアを使用することで、フォールバック戦略の設計や、サービスの可用性の最適化ができます。たとえば、セカンダリ ストアは、プライマリ ストアで発生するあらゆる種類のインシデントに対応するフォールバックとして機能し、サービスのデータ アクセスを保証します。
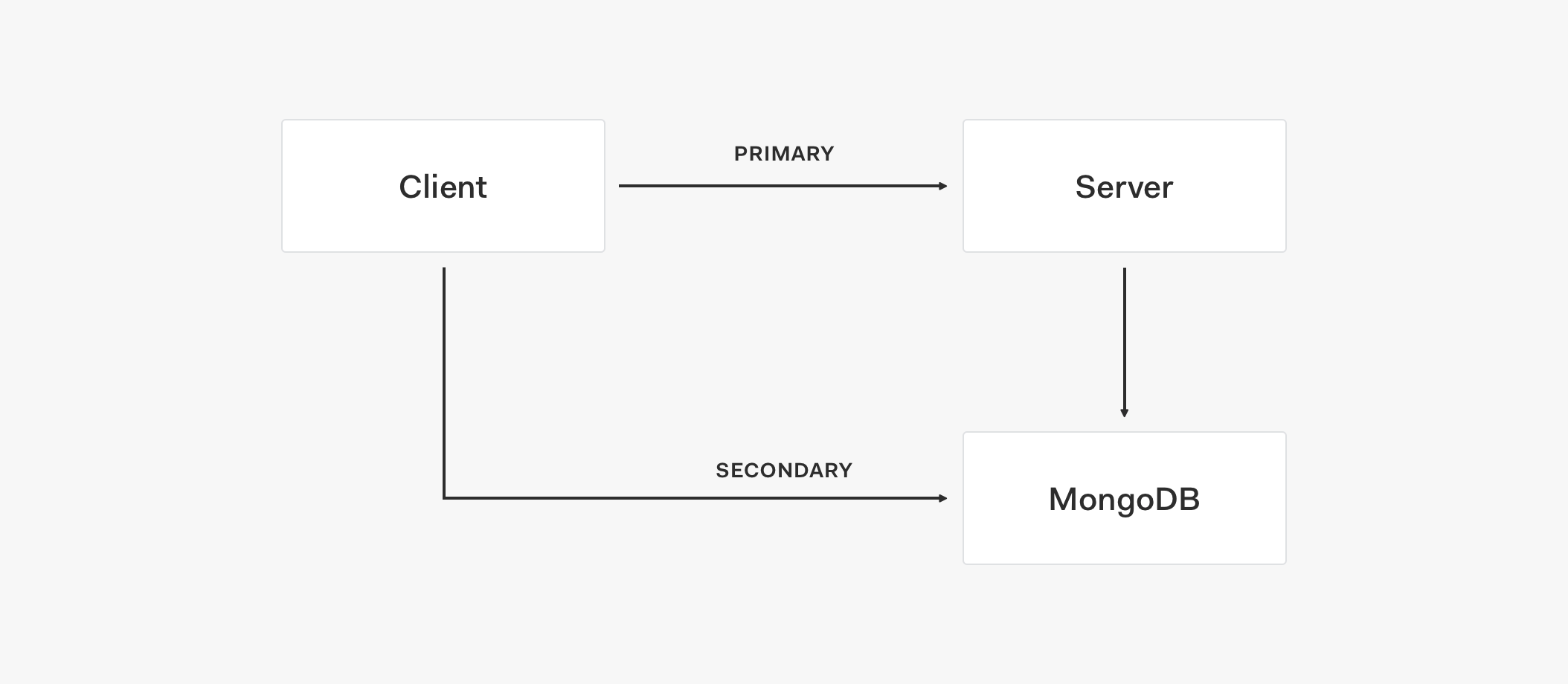
このトポロジのアーキテクチャ フローを見てみましょう。
- クライアントがプライマリ ストアへの接続を試行し、API を使用してデータを取得します。
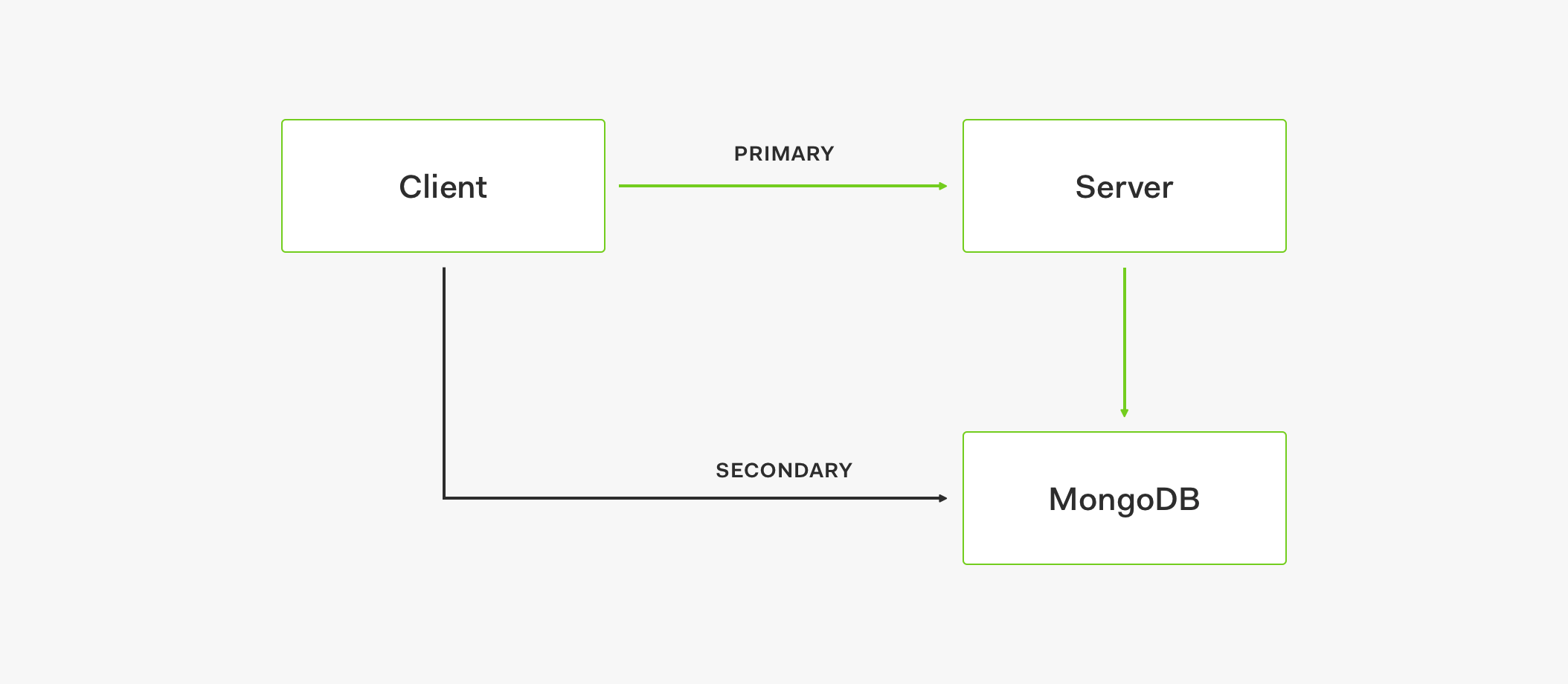
- API が何らかの原因によって停止している場合、5 回接続を試行した後、ロジック サーキットがオープンします。
- オープンしたサーキットは、クライアントからのリクエストをセカンダリ ストアに送信します。
- その後、データはセカンダリ ストアから取得されます。
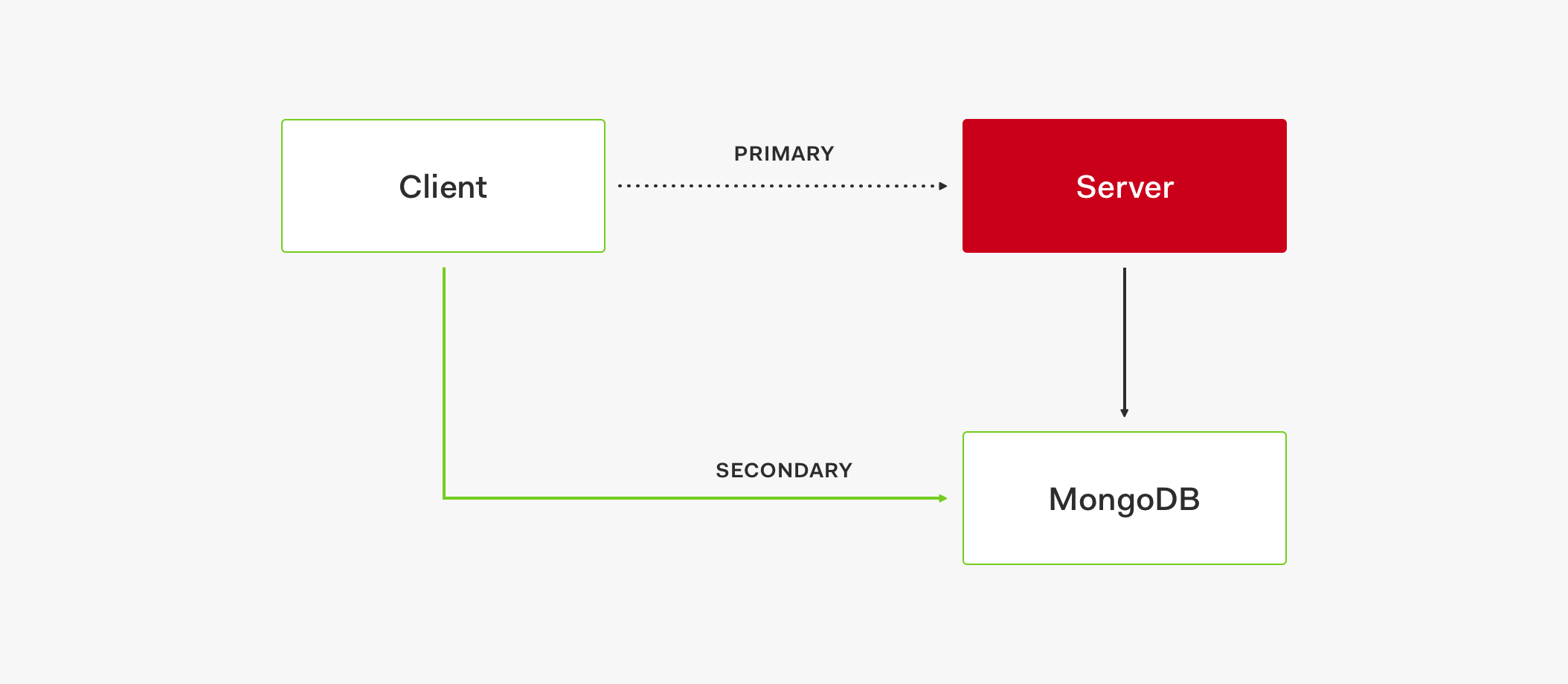
このフローでは、パフォーマンスの低下やその他の問題が発生する可能性はありますが、少なくともサービスは稼働できます。また、ストアには自己回復機能があります。プライマリ ストアが再び稼働すれば、このサーキットは閉じ、プライマリ ストアを使用する状態に戻ります。
メリット
- サーキット ブレーカーで障害に対処できる
- 自動的にフォールバックして回復する
- 基盤となるプロバイダーを抽象化することで、企業の成長に合わせて拡張できる
- サービスごとにアクセス方法が異なってもデータを照会できる
デメリット
- 追加のインフラストラクチャとメンテナンスが必要
- 追加のコストがかかる
- 両方のストアについてキャパシティ プランニングを実施するのが難しい
- プライマリ ストアが停止している場合、すべてのリクエストがセカンダリ ストアに送信されます。
- セカンダリ ストアのキャパシティとその地域のトラフィックを把握しておく必要があり、していないとシステムのパフォーマンスに大きく影響します。
- キャパシティ プランニングが簡単ではない
- トラフィック、ユースケース、クライアント アプリケーションに依存します。
- 内部キャッシュを持つアプリケーションかどうかを考慮する必要があります。
- サービスの拡張戦略を練る必要があります。
- サーキットのオープン中に大規模なサービス停止が起きるのを避けるために、ストアのバランスを保つ必要がある
- サーキットのオープン中にリクエストが殺到するのを避ける必要があります。
- リクエストによってセカンダリ ストアがあふれ、クラッシュする可能性があります。
このトポロジが抱えるこれらの問題を解決するために、もう 1 つのレイヤーとして、キャッシュを追加することにしました。次のセクションで説明します。
ストアへのキャッシュの追加
この段階でレイヤーは、キャッシュ、プライマリ ストア、セカンダリ ストアの 3 つとなりました。
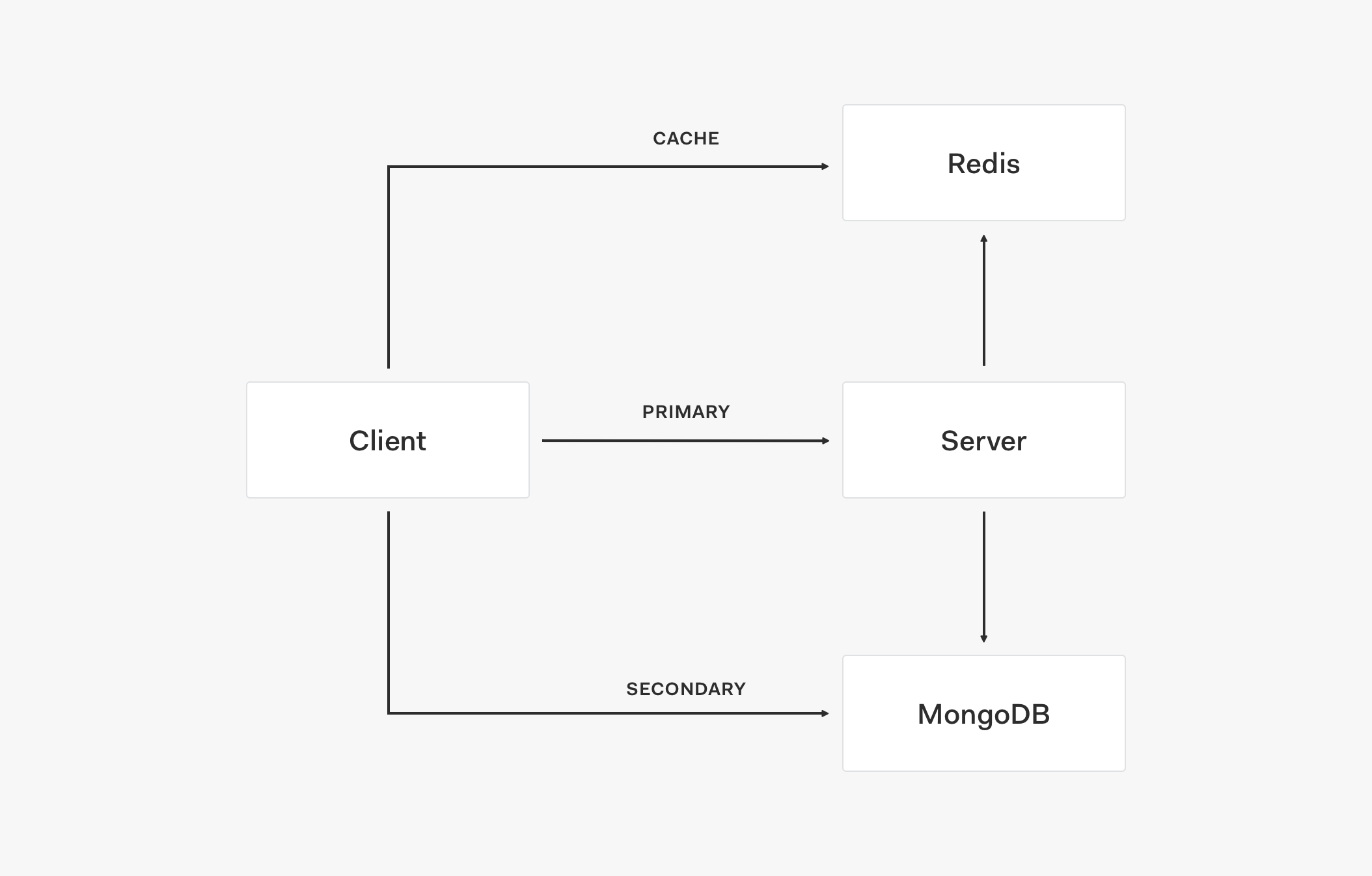
この 3 つのレイヤーが相互にどう連携するのかを、トポロジのアーキテクチャ フローを細かく追って見ていきましょう。
- このクライアントでは最初に、Redis などのキャッシュからのデータを受け取ります。
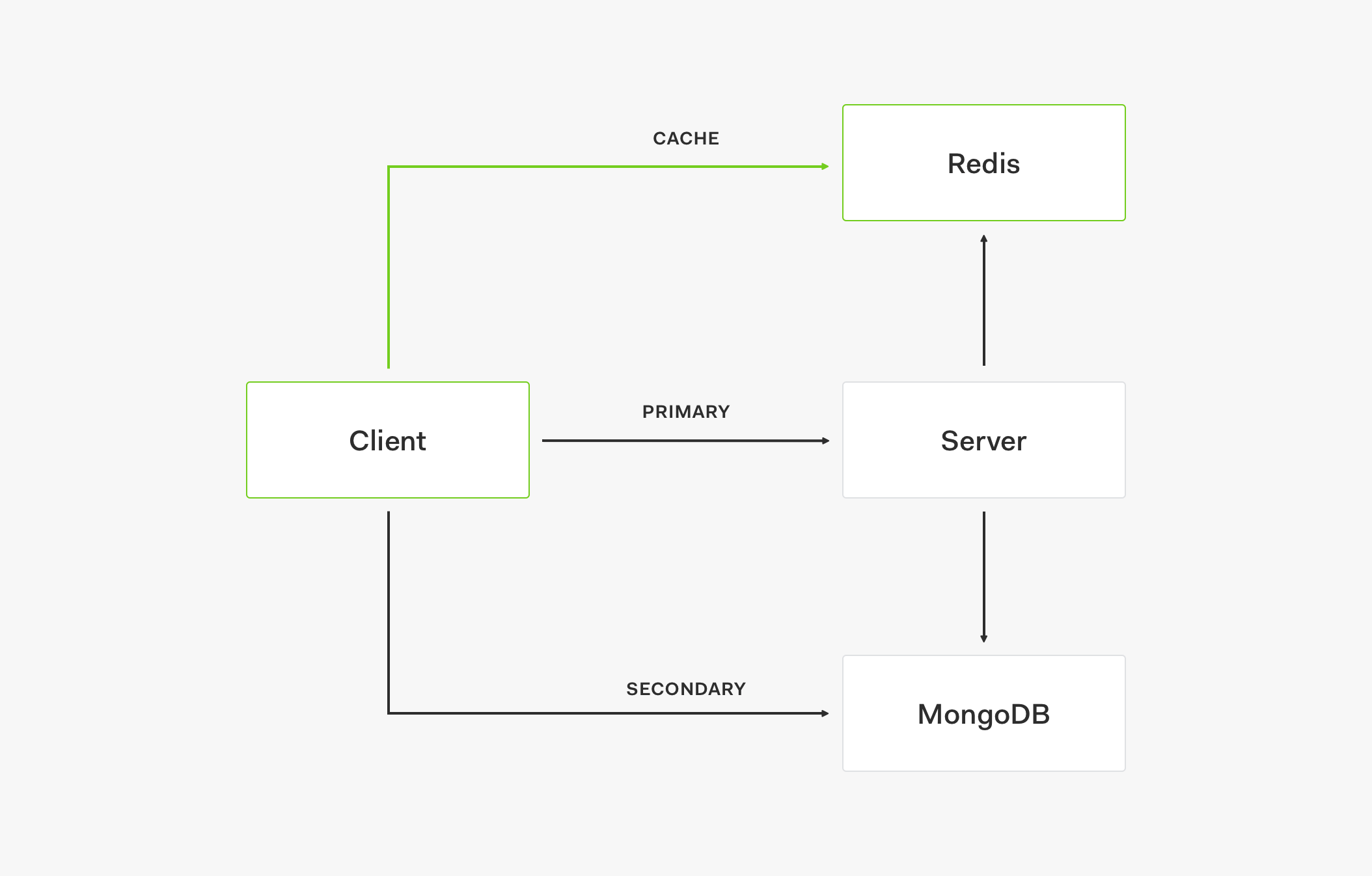
- データがキャッシュにない場合、リクエストはプライマリ ストアに送信されます
- プライマリ ストアがレスポンスとしてデータを返すときに、キャッシュも更新されます。
- その後のリクエストでは、データはキャッシュから取得されます。
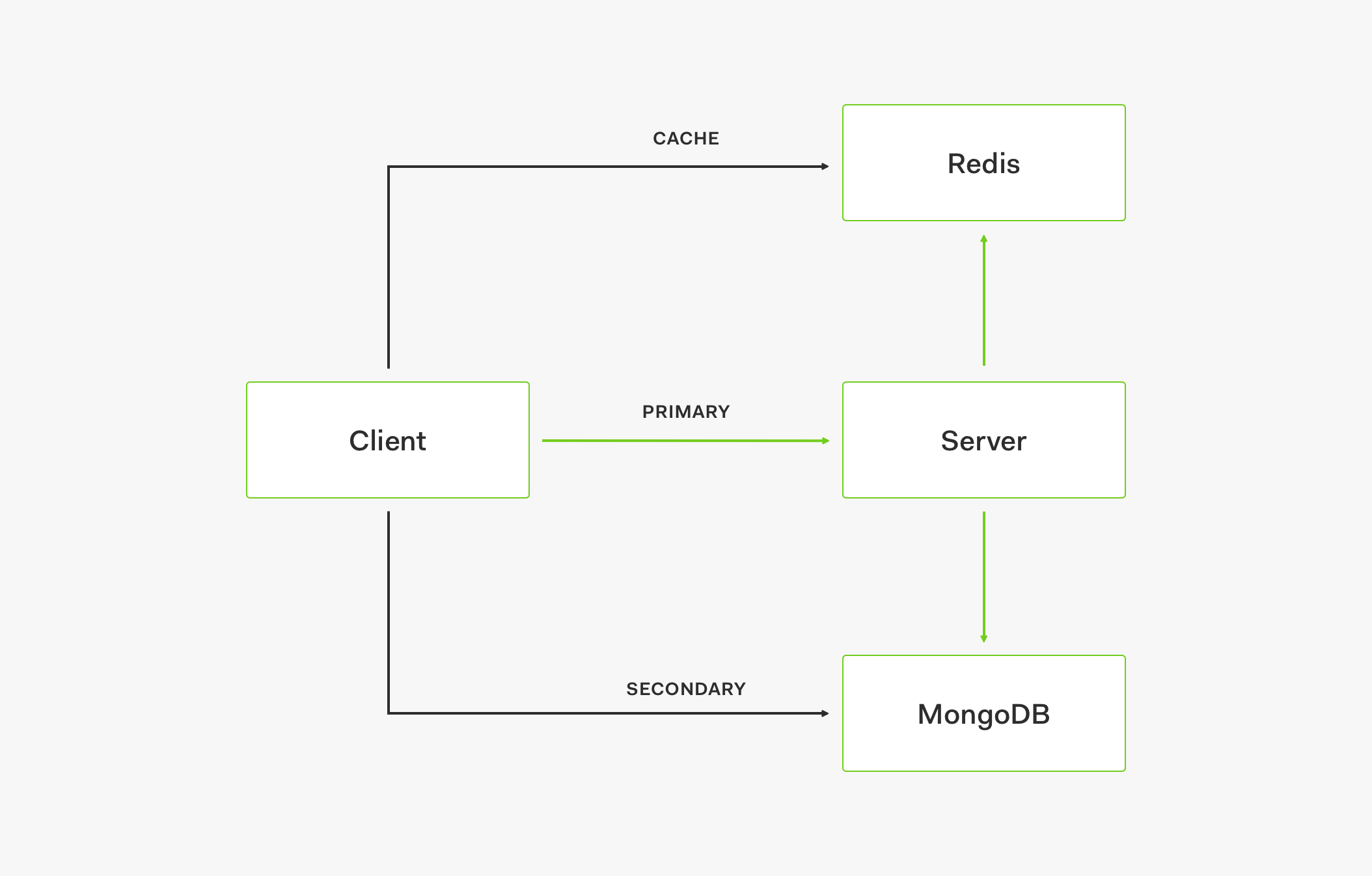
キャッシュは稼働しているものの必要な値が存在しない (キャッシュが古い) 状況で、プライマリ ストアが停止している場合、リクエストは、フォールバックとして機能するセカンダリ ストアで処理されます。
キャッシュとプライマリ ストアの両方が停止している場合も、リクエストはセカンダリ ストアで処理されます。
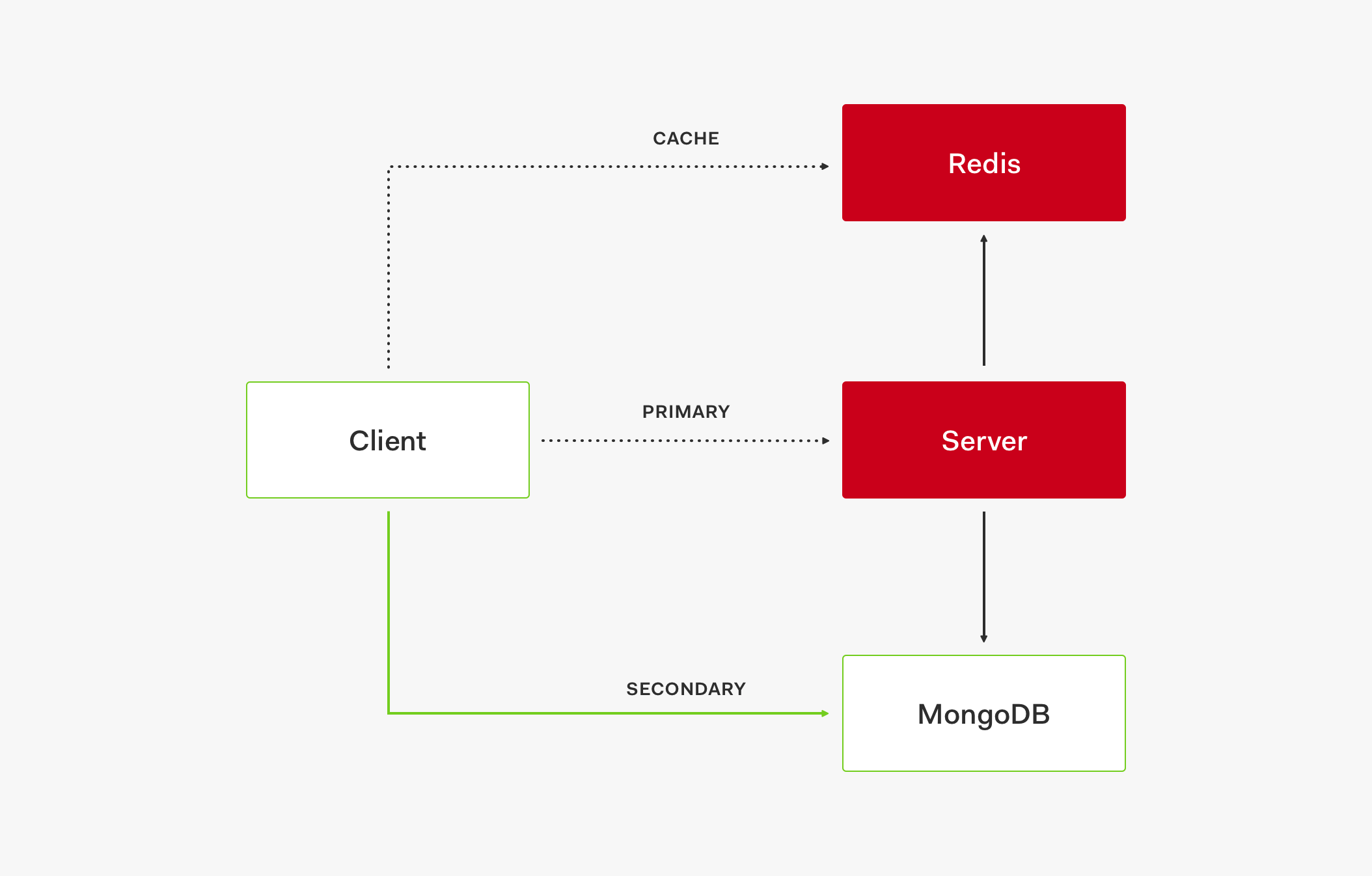
- サービス停止が引き起こされるのは、キャッシュ、プライマリ ストア、セカンダリ ストアの 3 つすべてのレイヤーが停止したときだけです。
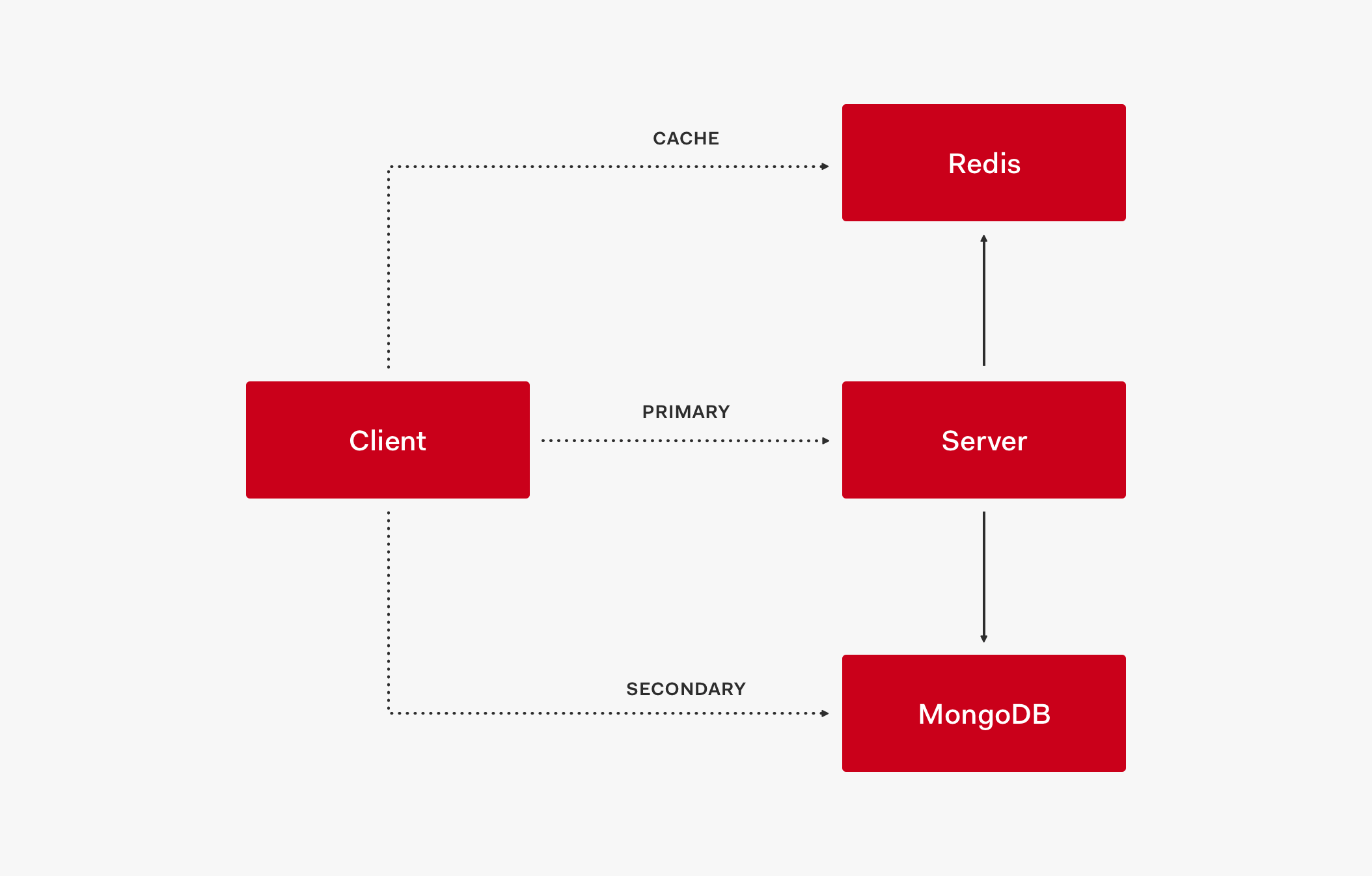
この 3 つのレイヤーのシステム モデルによって高い可用性が確保され、サービスの稼働状態が維持されます。
Auth0 の認証サーバーと同じ方法で一部のサービスの稼働状態を維持できるため、このアーキテクチャにはとても大きなメリットがあります。
メリット
- 応答時間が短縮される
- 変更頻度の低いデータ (このケースでは機能フラグ) に最適です。
- フラグをキャッシュする最大の利点です。
- ストアへの負荷が減る
- ストア利用時と同様のメリットがある (サーキット ブレーカー、回復)
デメリット
- インフラストラクチャの追加と保守にさらにコストがかかる
- 分散キャッシュが必要になります。
- 新たに別の障害点を考慮する必要がある
- キャッシュを利用すると、(適切な time to live (TTL) , キャッシュの無効化)などの検討事項が増える
- ストア利用時と同様のキャパシティ プランニング関連の課題がある
これで、機能フラグ サービスのサービス アーキテクチャが大きく進化しました。進化の 1 つは、必要に応じてモデル上のさまざまなレイヤーを切り替えられる優れたサーキット ブレーカー メカニズムが備えられたことです。では、Auth0 の現状のサーキット ブレーカー戦略について詳しく説明していきましょう。
サーキット ブレーカー
サーキット ブレーカーはソフトウェア アーキテクチャに実装する設計パターンの 1 つであり、Michael Nygard 氏の著書Release It!で広く知られるようになりました。このパターンを使用することで、システム障害を検出し、メンテナンスやサービス停止などのイベント中に失敗しそうな操作が試行されるのを防ぐことができます。
Auth0 では、エンジニアリング責任者の José Romaniello が作成した disyuntor というカスタム ライブラリを使用してサーキット ブレーカー パターンを実装しています。
Auth0 のエンジニアはこのライブラリを活用して、例外や問題ごとにさまざまなパスを簡単に構成しています。
const disyuntor = require('disyuntor'); const dnsSafeLookup = disyuntor.wrapCallbackApi({ //This is used in error messages. name: 'dns.lookup', //Timeout for the protected function. // timeout: '2s', //The number of consecutive failures before switching to open mode //and stop calling the underlying service. // maxFailures: 5, //The minimum time the circuit remains open before doing another attempt. // cooldown: '15s', //The maximum amount of time the circuit remains open before doing a new attempt. // maxCooldown: '60s', //optionally log errors onTrip: (err, failures, cooldown) => { console.log(`dns.lookup triped because it failed ${failures} times. Last error was ${err.message}! There will be no more attempts for ${cooldown}ms.`); }, onClose: (cooldown) => { console.log(`dns.lookup circuit closed after ${cooldown}ms.`; } // //optional callback to prevent some errors to trigger the disyuntor logic // //in this case ENOTFOUND is passed to the callback and will // //not trigger the breaker eg: // trigger: (err) => err.code !== 'ENOTFOUND' }, dns.lookup); //then use as you will normally use dns.lookup dnsSafeLookup('google.com', (err, ip) => { if (err) { return console.error(err.message); } console.log(ip); })
たとえば、4 回試行に失敗して問題が発生した場合は、サーキットを開いて別のパスに進みます。このパスに進むと、回復、フォールバック、任意の代替手段をコード内で選択できます。サーキット ブレーカーのトリップが発生するたびに、
onTrip// Configure protected functions with circuit-breaker const disyuntorOptions = { name: "client", maxFailures: 4, cooldown: "15s", timeout: options.api && options.api.type === "rest" ? "5s" : "1s", trigger: err => { // increment the number of attempts only for transient errors return this._isTransientError(err); }, onTrip: (err, failures) => agent.logger.error( { err }, `An error occurred while reading from primary store after ${failures} attempts.` ) };
上記は、Auth0 の機能フラグ サービスに設定している基本構成です。4 回失敗するごとにサーキットをオープンし、セカンダリ ストアにアクセスします。また、15 秒クールダウンしてから再度プライマリ ストアへのアクセスを試行します。
サービスには、HapiJS による RESTful 実装と、gRPC による別の実装があります。そのためサーキット ブレーカーの構成には、API リクエストの種類に応じてタイムアウトの長さも指定しています。HapiJS の場合、リクエストの処理に 5 秒以上かかると自動的にタイムアウトします。gRPC の場合は 1 秒以上でタイムアウトします。
const disyuntorOptions = { //... timeout: options.api && options.api.type === "rest" ? "5s" : "1s" //... };
さらに、タイムアウトはトリガーによっても変わります。
const disyuntorOptions = { //... trigger: err => { // increment the number of attempts only for transient errors return this._isTransientError(err); } //... };
エラーを検出した際は、一時的なエラーなのかどうかを判断することも重要です。これは、サーキットのオープンを保証するエラーとそうでないエラーがあるためです。たとえば、Auth0 の機能フラグ サービスでは、無効なフラグはサーキットのオープンが必要なエラーではなく、クライアント アプリケーションからの不正なリクエストとして扱われます。
disyuntor_getFlagsFromStore(entityId, flagsIds) { const self = this; return self.protectedGetFlags(entityId, flagsIds) .then(flags => { return flags; }) .catch(err => { if (!self.stores.secondary || !self._isTransientError(err)) { // don't use fallback for non transient errors throw err; } agent.logger.error(err.error || err, 'getFlags.fromPrimaryStore.error'); return self.stores.secondary.Entities.getFlags(entityId, flagsIds) .then(flag => { return flag; }) .catch(err => { throw err; }); }); }
disyuntorPromisecatchまずキャッシュにアクセスします。
_getFlagsFromStore(entityId, flagsIds) { // ... }
キャッシュに値がない場合、gRPC API などでプライマリ ストアにアクセスします。
_getFlagsFromStore(entityId, flagsIds) { // ... return self.protectedGetFlags(entityId, flagsIds) .then(flags => { return flags; }) .catch(err => { // ... }); }
4 回試行してプライマリ ストアがリクエストの処理に失敗したら、セカンダリ ストア (MongoDB) にアクセスしてフラグを取得します。
_getFlagsFromStore(entityId, flagsIds) { // ... return self.protectedGetFlags(entityId, flagsIds) .then(flags => { return flags; }) .catch(err => { if (!self.stores.secondary || !self._isTransientError(err)) { // don't use fallback for non transient errors throw err; } agent.logger.error(err.error || err, 'getFlags.fromPrimaryStore.error'); return self.stores.secondary.Entities.getFlags(entityId, flagsIds) .then(flag => { return flag; }) .catch(err => { throw err; }); }); }
キャッシュとプライマリ ストアに問題がある場合、最後のリソースであるセカンダリ ストアにアクセスします。これですべてのサービスにフラグを提供し続けることができます。
最後に、キャッシュ戦略についてもう少し詳しく見ていきましょう。
“サーキット ブレーカーは、システム障害を検出し、メンテナンスやサービス停止などのイベント中に失敗しそうな操作が試行されるのを防ぐ設計パターンです”
Tweet This
キャッシュ
Auth0 では、単純に Redis をキャッシュとして追加し、複雑な構成にしない戦略を取っています。
"use strict"; const _ = require("lodash"); module.exports = class CacheConfigurator { constructor(strategies) { this.Strategies = _.extend( { redis: require("./redis-cache"), memory: require("./memory-cache") }, strategies ); } build(options) { if (!options) { return; } const strategy = this.Strategies[options.type]; if (!strategy) { throw new Error("Unknown cache strategy " + options.type); } return new strategy(options); } };
CacheConfiguration_getFlagFromCache(entityId, flagId) { return this.cache ? this.cache.getEntityFlag(entityId, flagId) : Promise.resolve(); }
キャッシュが構成されている場合は、プロバイダーからフラグを取得します。それ以外は
Promiseこのキャッシュ戦略は自由に拡張できます。たとえば、Redis の代わりに分散キャッシュとして MongoDB を使用することもできます。プライマリ ストアとセカンダリ ストアについても同様に拡張可能です。プライマリ ストアとして PostgreSQL を選択したり、現在や将来の要件に合うような他のプロバイダーを配置したりすることもできます。
災害シナリオの管理
Auth0 の自己回復サービス アーキテクチャは、とてもシンプルです。ここまで見てきたとおり簡単に災害管理ソリューションを実装できます。
🛑 キャッシュがタイムアウト
✅ プライマリ ストアに接続
🛑 キャッシュが停止
✅ プライマリ ストアに接続
🛑 プライマリ ストアがタイムアウト
✅ 一定回数の試行後、セカンダリ ストアへのサーキットを開く
🛑 プライマリ ストアが停止
✅ 一定回数の試行後、セカンダリ ストアへのサーキットを開く
🛑 セカンダリ ストアが停止
🙏 すべての機能が停止! 復旧を祈るのみ...
理想は、サービス機能をサポートするデータを独自のデータベースに移動することです。Auth0 は機能フラグのデータを、個別のバックアップ機能と監視機能を備えた独自の別 MongoDB インスタンスに移しています。
Auth0 サービス アーキテクチャの今後の展望
サービス アーキテクチャをさらに最適化するために、Auth0 ではインフラストラクチャとシステムを次のようにアップグレードする予定です。
- キャッシュ戦略を改良する
- キャッシュ インスタンスのサイズを増やし、各地域で信頼を高める
- キャッシュ レイヤーにサーキット ブレーカーを導入する
- Redis に障害が発生した場合、メモリ キャッシュにアクセスできるようになります。
- 受信リクエストをメモ化して、パフォーマンスを高速化する
- Promises をキャッシュしてその解決した結果を返せるようになります。
まとめ
私たちがなぜ独自の機能フラグ サービスを構築したかというと、複数のプロバイダーを利用したり、任意の Auth0 アプライアンスに使用したりできるホスト バージョンの機能フラグ サービスを求めていたからです。独自に構築することで、プロバイダーを柔軟に選択できるようになり、ニーズに合わせてカスタマイズできるようになりました。LaunchDarkly などのサービスも検討しましたが、必要なサービス要件を満たしていませんでした。構築した機能フラグ サービスで最も満足しているのは、サービスの複雑さをレイヤーごとに決められる点です。将来的には、このプロジェクトをオープン ソース化することも視野に入れています。
Auth0 について
Auth0 は、アプリケーションビルダーのためにつくられた最初のアイデンティティ管理プラットフォームであり、カスタムビルドアプリケーションに必要とされる唯一のアイデンティティソリューションです。世界中のアイデンティティを守り、イノベーターがイノベーションを起こせるようにするというミッションのもと、Auth0 はシンプルで、拡張性のある、スケーラブルなプラットフォームを提供し、あらゆるオーディエンスのために、あらゆるアプリケーションのアイデンティティを守ります。Auth0 は毎日 1 億回以上のログインを保護し、法人企業が信頼されるエレガントなデジタルエクスペリエンスを世界中の顧客に提供できるようにします。
より詳しい情報に関して、https://auth0.com/jp/もしくは@auth0_jp on Twitterをご覧ください。
About the author

Dan Arias
Staff Developer Advocate
The majority of my engineering work revolves around AWS, React, and Node, but my research and content development involves a wide range of topics such as Golang, performance, and cryptography. Additionally, I am one of the core maintainers of this blog. Running a blog at scale with over 600,000 unique visitors per month is quite challenging!
I was an Auth0 customer before I became an employee, and I've always loved how much easier it is to implement authentication with Auth0. Curious to try it out? Sign up for a free account ⚡️.View profile